CVPR Highlights 2015
Having just returned from CVPR 2015 in Boston, the sense of deep learning excitement was palpable. Getting in to the deep learning workshop was like boarding a Tokyo train. So, in the spirit of Andrej Karpathy’s excellent CVPR highlights (which I read as an undergrad), I decided to write up some of my own impressions from the conference. This is by no means a complete representation of all the great work that was there, just a few cool things that I noticed.
Picking the low-hanging deep fruit
Clearly there are still many new applications being found for convolutional neural networks (CNNs). In many problem domains, researcher’s are still reporting significant performance improvements when using CNNs to replace other discriminatively trained classifiers. One conference attendee I spoke to described this as “picking the low-hanging deep fruit”. In any case, citations of Alex Krizhevsky’s seminal 2012 NIPS paper must be through the roof. In fact, in many papers this CNN architecture (‘AlexNet’) is still being reused, even though it is now 3 years old.
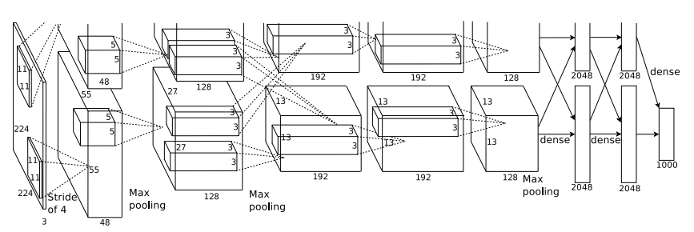

I am going to claim with no justification whatsoever, that this image of AlexNet was as common at CVPR this year as the Lena image. Given that AlexNet is a line drawing and Lena is a 1972 Playboy model, this would be quite an achievement.
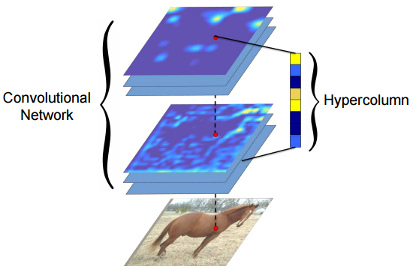
Using low and mid-level CNN activations
One of the key developments in CNNs this year was the increasing use of feature representations that include low and mid-level convolution layer activations, not just output layer activations. The intution behind this approach seems to be that the while the output layers encode the ‘what’ of the problem, the lower layers encode the ‘where’. Certainly it seems that for tasks that include a localisation component, such as image segmentation, this looks like it is now the dominant approach. I counted at least four papers that, at least at first glance, appeared to contain variations on the this common idea, which was variously described as ‘hypercolumns’, ‘deep jets’, ‘zoom-out features’ and ‘the treasure beneath convolutional layers’.
Looking at these papers side-by-side, the most fascinating observation for me is that the best performance on Pascal VOC 2012 semantic segmentation (which was ‘zoom-out features’ by a significant margin) was achieved using a network pre-trained on ImageNet, as-is. The base network was not even fine-tuned on the task at hand. This certainly illustrates the power of using activations from every layer of a CNN.
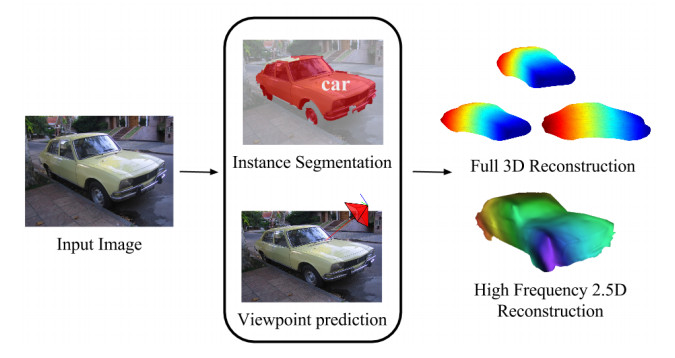
3D from a single image
This year again featured an oral on reconstructing 3D from a single image (which was awarded best student paper) and also included a full day workshop on this task as well. It certainly seems that there is increasing attention focused on a challenge that only a few years ago would have been considered too difficult. Although current approaches require ground truth segmentation and keypoints for the training images, no doubt many researchers are working on relaxing these requirements. It will certainly be interesting to follow progress in this area.
Visualising deep networks
Some interesting work is being done on how to visualise feature activations with deep networks. This paper (Understanding Deep Image Representations by Inverting Them) proposed an optimisation method to sample the space of possible reconstructions for a given set of feature activations. This approach then illustrates some of the photometric and geometric invariances captured at each layer of the net, as illustrated in the image below. I also caught a fascinating invited workshop talk by Antonio Torralba that touched on this topic as well. Check out this really nice interactive visualization of a deep network by his group at MIT.

Merging vision and language
It seems like rapid progress is being made on the problem of generating natural language image descriptions (aka image captioning), for example this paper (Deep Visual-Semantic Alignments for Generating Image Descriptions). I’ve heard it argued around the lunch table that this isn’t an important problem. Whether that’s true or not, it’s certainly a good yardstick for progress. I’m certainly looking forward to downloading Andrej Karpathy’s code from this paper and testing it out.

Other stuff
Yoshua Bengio’s invited talk at the deep learning workshop is chock-full of great references to some of the recent theory papers on deep learning.
Raquel Urtasun and Marc Pollefeys gave some really interesting talks on graphical models (including combining with deep networks). If I can find links I’ll post them, and then try and understand them!
There were many other great talks and papers as well, this is just a sample. What else did I miss?