Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, Lei Zhang
CVPR 2018 (Selected for Oral Presentation)
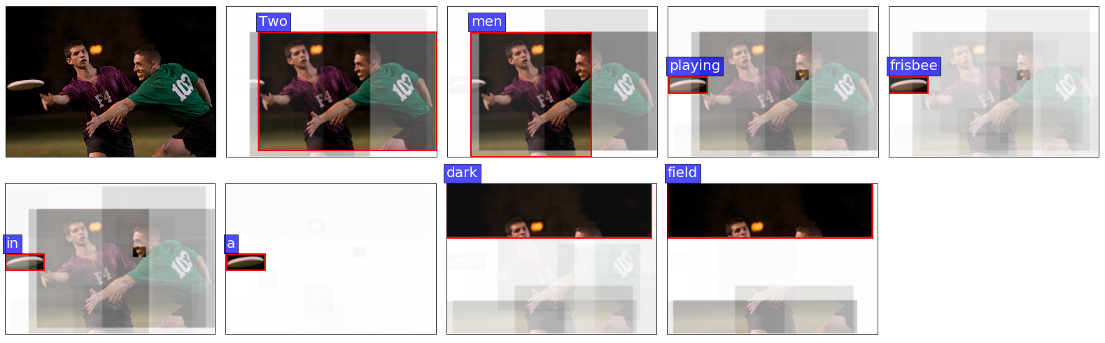
Top-down visual attention mechanisms have been used extensively in image captioning and visual question answering (VQA) to enable deeper image understanding through fine-grained analysis and even multiple steps of reasoning. In this work, we propose a combined bottom-up and topdown attention mechanism that enables attention to be calculated at the level of objects and other salient image regions. This is the natural basis for attention to be considered. Within our approach, the bottom-up mechanism (based on Faster R-CNN) proposes image regions, each with an associated feature vector, while the top-down mechanism determines feature weightings. Applying this approach to image captioning, our results on the MSCOCO test server establish a new state-of-the-art for the task, improving the best published result in terms of CIDEr score from 114.7 to 117.9 and BLEU-4 from 35.2 to 36.9. Demonstrating the broad applicability of the method, applying the same approach to VQA we obtain first place in the 2017 VQA Challenge.


Paper and Code
PDF Features Code Captioning Code Poster Slides
Reference
@inproceedings{Anderson2017up-down,
author = {Peter Anderson and Xiaodong He and Chris Buehler and Damien Teney and Mark Johnson and Stephen Gould and Lei Zhang},
title = {Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering},
booktitle={CVPR},
year = {2018}
}