SPICE: Semantic Propositional Image Caption Evaluation
Peter Anderson, Basura Fernando, Mark Johnson, Stephen Gould
Abstract
There is considerable interest in the task of automatically generating image captions. However, evaluation is challenging. Existing automatic evaluation metrics are primarily sensitive to n-gram overlap, which is neither necessary nor sufficient for the task of simulating human judgment. In this paper we hypothesize that semantic propositional content is an important component of human caption evaluation, and propose a new automated caption evaluation metric defined over scene graphs coined SPICE. Evaluations indicate that SPICE captures human judgments over model-generated captions better than other automatic metrics (e.g., system-level correlation of 0.88 with human judgments on the MS COCO dataset, versus 0.43 for CIDEr and 0.53 for METEOR). Furthermore, SPICE can answer questions such as which caption-generator best understands colors? and can caption-generators count?
ECCV 2016 Paper
SPICE: Semantic Propositional Image Caption Evaluation. Peter Anderson, Basura Fernando, Mark Johnson and Stephen Gould. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, the Netherlands, October 2016.
If reporting SPICE scores, please reference the SPICE paper:
@inproceedings{spice2016,
title = {SPICE: Semantic Propositional Image Caption Evaluation},
author = {Peter Anderson and Basura Fernando and Mark Johnson and Stephen Gould},
year = {2016},
booktitle = {ECCV}
}
Code
SPICE can be downloaded via the link below. This will download a 31 MB zip file containing (1) the SPICE code jar, (2) the libraries required to run SPICE (except for Stanford CoreNLP) and (3) documentation / source code for the project. Unzip this file, download Stanford CoreNLP using the included download script and you’re ready to use it.
Alternatively, a fork of the Microsoft COCO caption evaluation code including SPICE is available on Github. SPICE source is also on Github.
MS COCO evaluation code on Github SPICE source on Github
A note on the magnitude of SPICE scores: On MS COCO, with 5 reference captions scores are typically in the range 0.15 - 0.20. With 40 reference captions, scores are typically in the range 0.03 - 0.07. This is the expected result due to the impact of the recall component of the metric. On the MS COCO leaderboard, C40 SPICE scores are multiplied by 10.
Examples
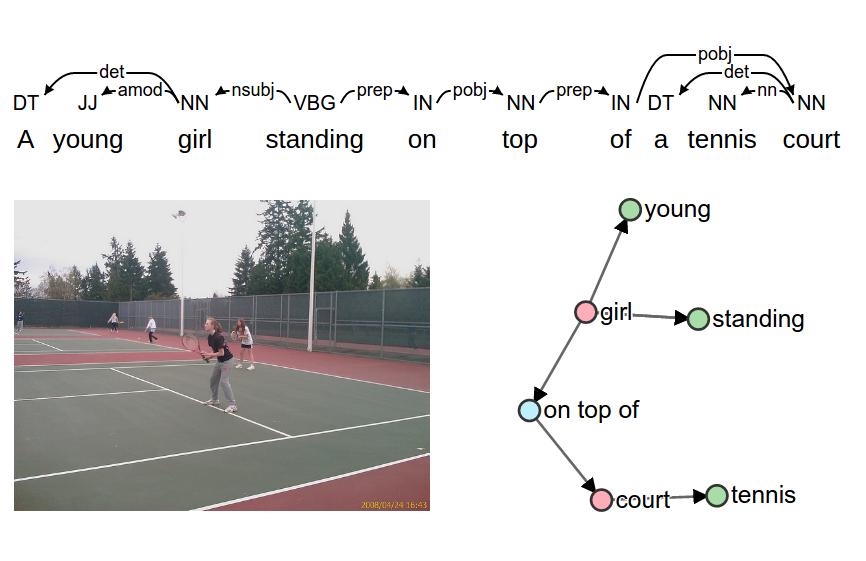
To help illustrate how SPICE works, in the interactive figures below we illustrate SPICE score calculations for a near-state-of-the-art model on 100 example images drawn from the Microsoft COCO captions validation set. Scene graphs contain objects (red), attributes (green), and relations (blue). Correctly matched tuples are highlighted with a green border. Note that images have been randomly selected so some scene graph parsing and matching errors can be observed.
Reference captions
Reference scene graph
Candidate caption & scene graph
Microsoft COCO Evaluations
System-Level Correlation
We are gratefull to the COCO Consortium for agreeing to run our SPICE code against entries in the 2015 COCO Captioning Challenge. The plots below illustrate evaluation metrics vs. human judgements for the 15 entries, plus human-generated captions. Each data point represents a single model. Only SPICE (top left) scores human-generated captions significantly higher than challenge entries, which is consistent with human judgement. A full description of the human evaluation data and model references can be found here.
Choose Evaluation: